
HAWQ is a modern distributed and parallel query processor on top of HDFS that gives enterprises the best of both worlds: high-performance query processing with SQL, and scalable open storage. When the data is directly stored on HDFS, it provides all features of Hadoop. Using HAWQ, SQL can scale up on Hadoop like petabyte range of datasets. HAWQ natively reads data from and writes data to HDFS. It has true SQL capabilities that include being SQL standards complaint, ACID complaint, and cost based query optimizer. It allows users to connect to HAWQ via most popular programming languages and supports ODBC and JDBC. HAWQ also supports columnar or row-oriented storage.
HAWQ can tolerate disk level and node level failures. It can coexist with MapReduce, HBase, and other database technologies common in Hadoop ecosystem. It supports traditional OLAP as well as advanced machine learning capabilities like supervised and unsupervised learning, inference, and regression.
HAWQ’s industry leading performance is achieved by dynamic pipelining, a parallel data flow framework, to orchestrate query executions. HAWQ essentially breaks complex queries into smaller tasks and distributes them to query processing units for execution and dispatched to segments that work together to deliver a single result set. HAWQ was benchmarked against Hive and Impala that were deployed on Pivotal Analytics Workbench (AWB) that clearly showed the industry leading performance in action. Here are the performance results for five real world queries on HAWQ, Hive, and Impala.
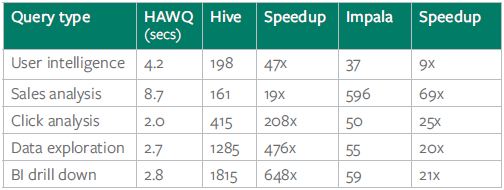
Performance results for five real world queries on HAWQ, Hive
and Impala
Read this white paper – Pivotal HD: HAWQ, A true SQL Engine for Hadoop, for more details.

