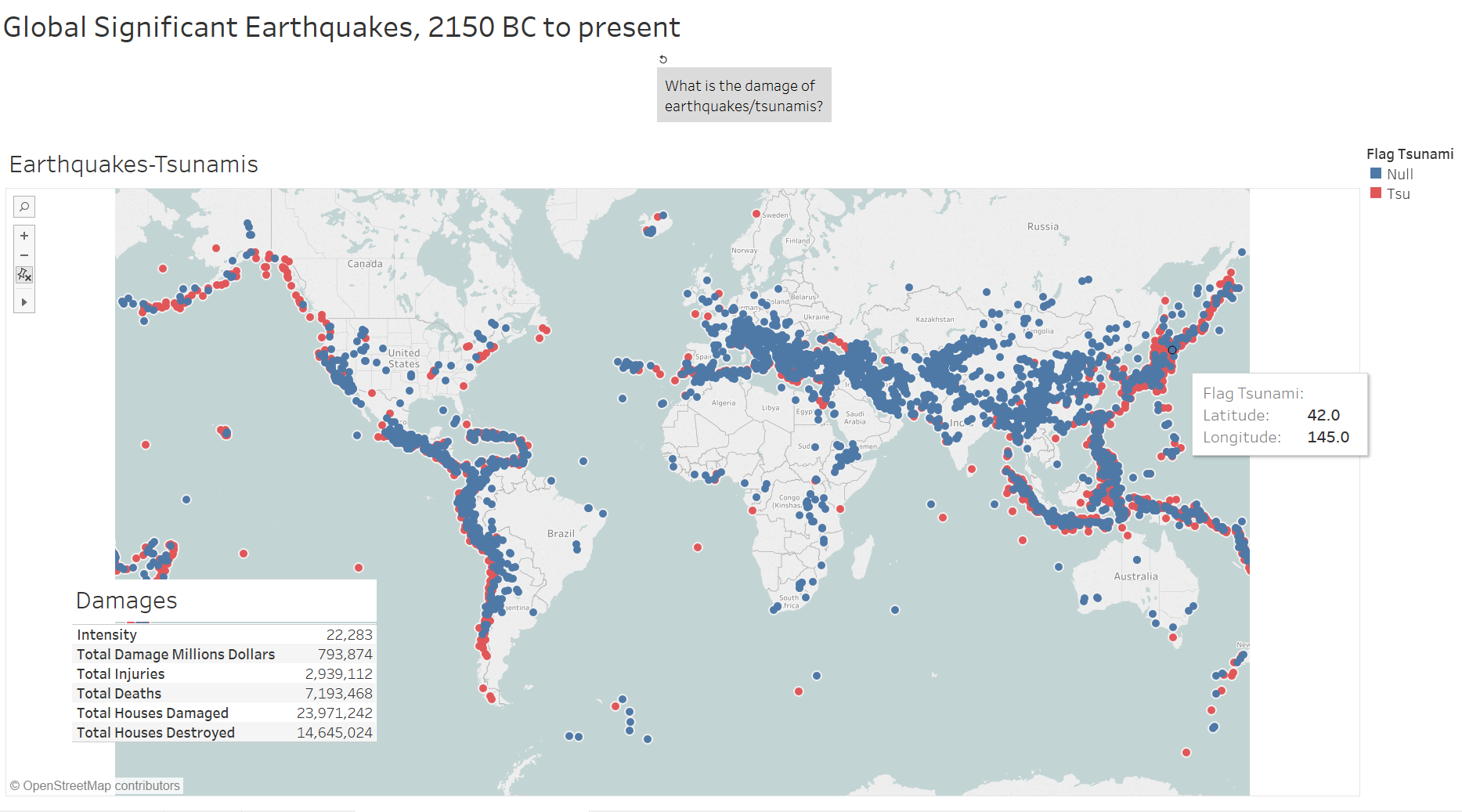
My recent speech on ethics seemed to have touch some nerves. It was that I touched “uncomfortable” topics and very specifically –swastika, syphilis, and voter fraud commission. Suggestion was given to stick to neutral topics. I thought this post would be place where I can redirect future questions/comments/suggestions.
Before I defend myself, I just want to make one thing clear. When I talk ethics, I’m not a moral arbiter. I’m just like you regular Jane (or Joe) – a law abiding, tax paying, boring neighbor who you would just nod politely and move along unless you got some weird quirks like technology, magic realism, historical fiction, painting, home cooking, or native gardening to name a few, then we can talk all day. That said, I want to help people to be aware of complex situations, ask questions to understand better, and enable them to arrive at a decision that aligns with their own/business values. When you ask someone in position of authority or expertise to give a definitive judgement on whether a decision is right or wrong, you could be just passing your responsibility. This would lead to “confirmation bias” – I conform you and you conform me – and eventually to ethical blindness in making business or personal decisions.
For example, let us say you are writing an algorithm for self-driving cars. One use case is break failure. If the breaks fail, there are two lanes, the car could possibly run over two little kids crossing the road in one lane or an old couple following them back in another lane. Which lane would you instruct your algorithm to choose? Now consider, what if one has a terminal disease and about to die in weeks or what if the old couple are your grandparents or what if the kids are your own? What is next step in your algorithm with that extra intelligence? Is there any right or wrong answer here? The situation here involved vehicular accident. It triggers some strong emotions in me – I lost a friend in road accident. Painful memories come to me anytime when I hear or read about it. I avoid talking about it. The discussion here is ethics of self-driving algorithms for cars. Focus on the situational complexity and try to avoid adding your own personal emotions to the discussion. This is the key thing in talking ethics. It is common to think “bad people makes bad decisions” – it is expected. When “good people makes wrong decisions” the devastations are stronger and deeper. When you make a business decision it should be for greater good for a larger number of people.
Understand the Bias –
Biases are stronger in influencing decisions. One person’s decision may seem completely irrational to you but if you look at it in the context it would make a perfect sense. At the same time, if your decisions are made on rigid contextual frames and biases, that could potentially lead to bad decisions. My example of swastika is to say as an Indian swastika is a positive bias (literal translation in Sanskrit su – goodness astika – happens here), symbol of goddess of wealth. This symbol could be traced to Indus Valley Civilization circa 3000 B.C.E. The same symbol negative bias to my American husband. It is essential to understand each other’s bias to have a successful marriage or even to live under the same roof. Try reading from “Understand the Bias” again to observe I did not qualify “negative bias” or launch into that part of history. I felt it is unnecessary to delve on that. It still evoked stronger emotions of making someone uncomfortable. It is better to leave emotions out when discussing complex situations to understand our biases.
Focus on the Context –
For “Informed Consent”, the legal precedence is the Common Rule. It started with the infamous Tuskegee Study. I felt it was essential to talk about the history because doctors are good people who had taken a Hippocratic Oath – “First Do No Harm”. The issue was such good people made a wrong decision to let the black sharecroppers suffer syphilis for three decades after the cure has been found. I understand syphilis is not a pleasant topic to discuss as the brush strokes of Claude Monet to immortalize the impressions of lily pond. My sister (microbiologist) may disagree with you – she is the only weirdo I’ve known who talks about dreadful viruses with the same warmth as one would talk about their favorite food. Once I overheard a discussion during dinner with her friends on “pappy” – I was thinking they were talking about someone’s pet dog only found that to be a discussion on HPV. My sympathies are with you – gross topic. It is easy to get carried away from the context – human rights – would you let your doctor run tests on you without your consent?
No Politics –
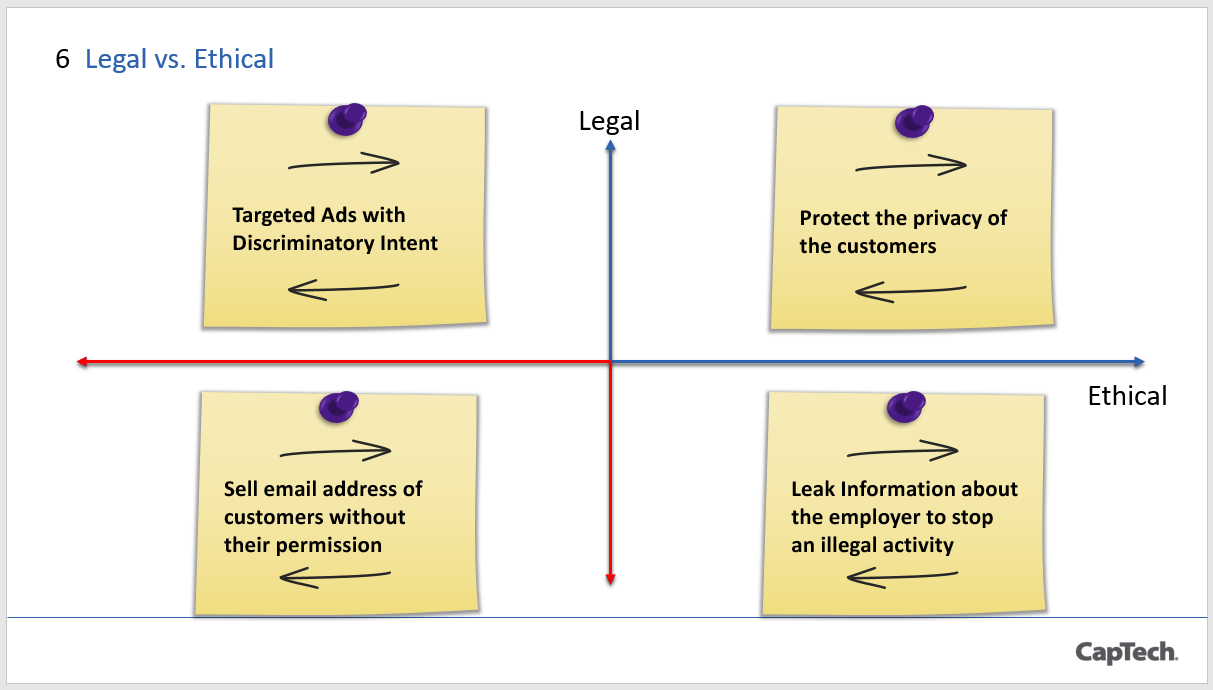
I wanted to bring attention of ethics in data storage. Recent one is that Voter Fraud Commission of 2017 wanted to store the data in the white house. I clearly said, “leave all the politics aside” – just think is it a clever idea to store the entire country’s voting history in one single place and that too white house?”. Situation to focus on is data storage in white house. One of the requirements to gain access to federal data centers is the person must be an American born in United States. Leaders, diplomats, and even tourists from other countries visit white house every day. I’m sure there are some restricted places in the white house but there are better places in the country if you want to store such sensitive, massive information. What is the check and balance here to stop anyone in white house abusing such sensitive data? Please observe my language here – I did not venture into politics although the topic is white house. Being silent is conforming an injurious behavior or decision. Fear of talking against the power or authority could lead to wrong decisions. In the story of Emperor’s New Clothes, only a little boy had the courage (or he was too young and naïve to feel the fear for the emperor) to tell that the emperor is naked.
Less Sensitive Case Studies –
All of us have our own values – we believe in our values and we fight for it. What you may consider as “less sensitive” could possibly be the sole existential purpose of another. It could possibly be taken under a different light. I’m a woman and taking case studies only about women’s issue could be considered as “pushing my own values” or talking about the location of Google’s data center location on San Andreas fault line could be taken as “hidden agenda against Google”. Although, I know if Google goes down, the earth would turn upside down, Google is a private company. United States government have reaches furthermore than Google could ever imagine. All case studies involving humans are equally sensitive whether it reaches small or big population.
To conclude, complex situations lead to difficult decision making. When you make that decision for you or your business, it is important to have a big picture, understand the biases, not to add personal emotions to the situation, and/or add fear of authority to it. Thanks to technologies like internet of things and big data to shrinking personal space, the need to analyze every atom of lives, add survival in aggressive business environment, we are living in ever changing world. That is exactly why we need ethics to peacefully coexist, to not to step on each other’s toes, and to create a better place to leave for our future generations.