
Apache Hadoop, introduced in 2005 has a core MapReduce processing engine to support distributed processing of large-scale data workloads. Several years later, there are major changes to the core MapReduce so that Hadoop framework not just supports MapReduce but other distributed processing models as well.
MapReduce 1.0
In a typical Hadoop cluster, racks are interconnected via core switches. Core switches should connect to top-of-rack switches Enterprises using Hadoop should consider using 10GbE, bonded Ethernet and redundant top-of-rack switches to mitigate risk in the event of failure. A file is broken into 64MB chunks by default and distributed across Data Nodes. Each chunk has a default replication factor of 3, meaning there will be 3 copies of the data at any given time. Hadoop is “Rack Aware” and HDFS has replicated chunks on nodes on different racks. JobTracker assign tasks to nodes closest to the data depending on the location of nodes and helps the NameNode determine the ‘closest’ chunk to a client during reads. The administrator supplies a script which tells Hadoop which rack the node is in, for example: /enterprisedatacenter/rack2.
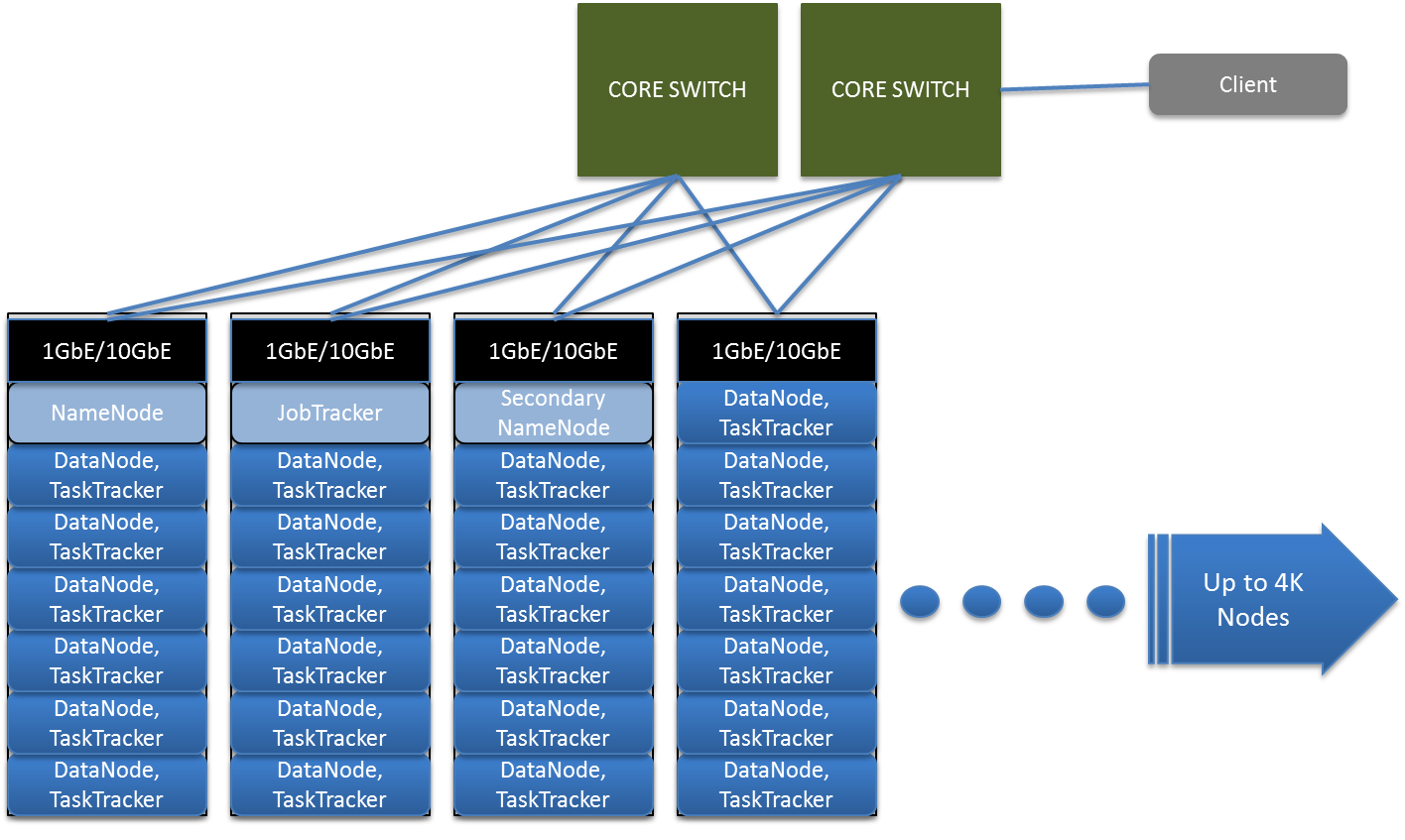
MapReduce 1.0
Limitations of MapReduce 1.0 – Hadoop can scale up to 4,000 nodes. When it exceeds that limit, it raises unpredictable behavior such as cascading failures and serious deterioration of overall cluster. Another issue being multi-tenancy – it is impossible to run other frameworks than MapReduce 1.0 on a Hadoop cluster.
MapReduce 2.0
MapReduce 2.0 has two components – YARN that has cluster resource management capabilities and MapReduce.

MapReduce 2.0
In MapReduce 2.0, the JobTracker is divided into three services:
- ResourceManager, a persistent YARN service that receives and runs applications on the cluster. A MapReduce job is an application.
- JobHistoryServer, to provide information about completed jobs
- Application Master, to manage each MapReduce job and is terminated when the job completes.
Also, the TaskTracker has been replaced with the NodeManager, a YARN service that manages resources and deployment on a node. NodeManager is responsible for launching containers that could either be a map or reduce task.
This new architecture breaks JobTracker model by allowing a new ResourceManager to manage resource usage across applications, with ApplicationMasters taking the responsibility of managing the execution of jobs. This change removes a bottleneck and let Hadoop clusters scale up to larger configurations than 4000 nodes. This architecture also allows simultaneous execution of a variety of programming models such as graph processing, iterative processing, machine learning, and general cluster computing, including the traditional MapReduce.


Reblogged this on Data Science and Big Data Analytics in practise.
Reblogged this on Rishi Arora.