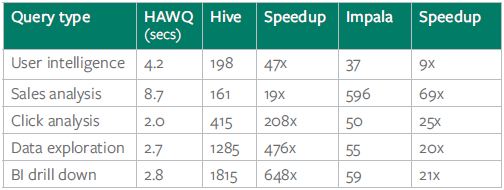
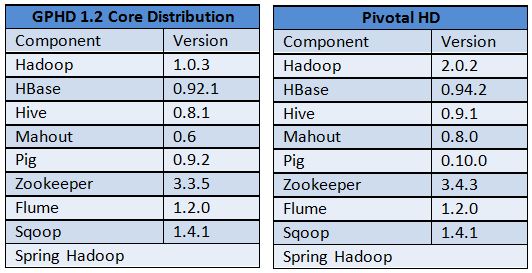
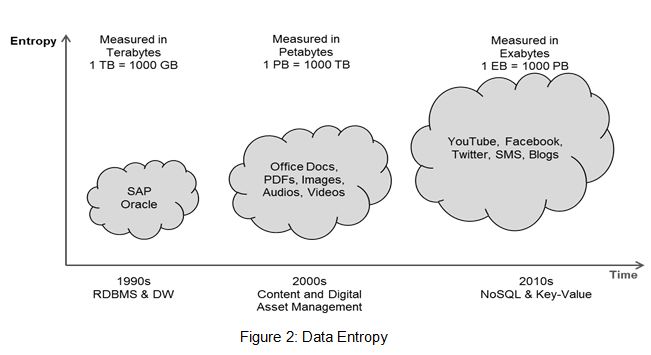
Arrow of Time is a term coined by British astronomer Arthur Eddington to describe time flows inexorably in one direction or the “asymmetry” of time. We can experience this time’s arrow in our everyday lives. Certain conditions, developments, or processes would lead to random events in the future that cannot be undone – such as ice cubes melting in a drink at room temperature or eggs cooked to an omelet cannot be reversed from water into ice cubes or from omelet to eggs.
Cause precedes effect – the causal event occurs before the event it affects. For example, dropping a glass of wine is a cause while the glass subsequently shattering and spilling the wine is the effect. Time’s arrow is bounded by this causality. The perception of cause and effect in the dropped glass of wine example is a consequence of the Second law of thermodynamics. Causing something to happen, controlling the future, creates correlations between the cause and the effect. These can only be generated as we move forwards in time. Moving backwards in time would render the scenario nonsensical. In the subjective arrow of time, we know the past but cannot change it; we don’t have direct knowledge of the future but predict in part, as it can be modified by our actions and decisions.
Special non-generic initial conditions of the universe are used to explain the time-directed nature of the dynamics we see around us. Many cosmic theories claim to use physical conditions and processes to set up the initial conditions of the standard big bang that created our physical universe. At this point of time, our existence is made easy with our own digital universe. Electromagnetic waves and signals, electronic circuits, copper wires to fiber channels, the need to achieve results quickly, efficiently, and accurately, led to the data big bang and subsequently the growth of our digital universe.
As the organizations go about their business and experiments in scientific research, more application are created every day that they are generating a tremendous amount of data. In a very positive socio-economic transformation, the rapid adoption of GPS enabled, media-rich smart mobile devices that integrates very well with social networking sites paved path to a new way of living – instant and spontaneous exchange of information among the individuals living across the world. The data is pouring out in a sheer pace that the volume of data by the end of this decade will be 50 times more than what we have today.
Data comes from variety of sources – business applications and scientific research, to personal data. The velocity in which it is generated is constant and instantaneous. This volume and variety is fuelled by the properties of cloud – affordability, agility, and extensibility. The volume of data thus created can be make sense when aggregating small sets that are somehow related to a larger set of the fragments to identify patterns, and define decisions and actions, to influence the effect in future get us the definition of big data.
Big data is any attribute that challenges the constraints of business needs or system capability. Take generation diversity for example – automated generation of data, such as images of weather prediction to manual entry such as tweets and blogs. Data generated thus are being updated at an amazing rate iteratively and incrementally. As we move forward in time, data about data is created, calculated or inferred. Despite of the size, speed or source of the data, big data is all about making sense out of chaos – find the meaning between the data that is constantly changing, finding the relationship between the data creation, understanding the interconnectedness that unlocks the value of big data – modeling events that affects future.
IDC’s digital universe study 2011 states that like our physical universe, the digital universe is something to behold — 1.8 trillion gigabytes in 500 quadrillion “files” — and more than doubling every two years. That’s nearly as many bits of information in the digital universe as stars in our physical universe.

Entropy is a measure of the disorder of a system. A well-organized system, like ice cubes or unbroken eggs, has low entropy; whereas a disorganized system, like melting ice cubes or broken eggs, has high entropy. Left to its own devices, entropy goes up as time passes. Entropy is the only quantity in the physical sciences that requires a particular direction for time. As we go “forward” in time, the second law of thermodynamics says that the entropy of an isolated system will increase. Hence, we can define entropy measurement is a way of distinguishing the past from the future from one perspective. A perceptual arrow of time is a continuous movement from the known past to unknown future. Expecting or predicting the unknown forms of future, is a norm that make something move towards it like setting a goal for a output of a system or in our case its hopes, dreams, and desires that make us move towards future.
As our digital universe grows in time, there is increase in the variety, velocity, and volume of data. This often leads to the disorder such as lack of governance, compliance, and security. We have standard governance, regulatory standards, and privacy laws that anticipate the future system.

Traditional BI fails to handle cases when data sets become progressively diverse and more granular against the results that are real-time and iterative. This kind of analysis requires organizations to capture exhaustive information from a specific moment in time before the entropy takes its effect on data. Conventional relational database systems does not support unstructured, high volume, fast-changing data—big data. It requires a new generation of technologies, tools, and analytic methods to extract value from our digital universe. Big data approaches are essential when organizations want to engage in predictive modeling, advanced statistical techniques, natural language processing, image analysis or mathematical optimization.
If we want big data to transform business and extract real value from the chaos of our digital universe it is extremely important to find the interconnectedness as we move forward in time. This will help business to make the best decision at the correct time and to deliver that to right people to execute. This is an attempt to apply the concept of arrow of time in big data to understand the interconnectedness in the digital universe to derive real business value from big data at an enterprise level.
References
http://www.emc.com/microsites/cio/articles/big-data-big-opportunities/LCIA-BigData-Opportunities-Value.pdf